
 We moved here from Arizona in 2003, and (as usual) it took us literally years to unpack everything. Some stuff was not meant to be unpacked, really–I left my vinyl collection and 8″ reel-to-reel mix tapes in boxes on the big shelf in the mechanical room, knowing they’d be there if I needed them but not actually expecting to need them. (I admit, I’ve gone looking in the boxes for a vinyl album a couple of times.) But there’s one box on the high shelf here in my office, containing stuff that was in odd places in my Scottsdale office, stuff that I wasn’t really sure where to put or what to do with. Every so often I sift through the box for an hour or so, trashing some stuff and filing some stuff and putting the rest of it back in the box. It’s only about 1/4 full now, so I guess I’m making some progress. It should be empty by the time I’m 80.
We moved here from Arizona in 2003, and (as usual) it took us literally years to unpack everything. Some stuff was not meant to be unpacked, really–I left my vinyl collection and 8″ reel-to-reel mix tapes in boxes on the big shelf in the mechanical room, knowing they’d be there if I needed them but not actually expecting to need them. (I admit, I’ve gone looking in the boxes for a vinyl album a couple of times.) But there’s one box on the high shelf here in my office, containing stuff that was in odd places in my Scottsdale office, stuff that I wasn’t really sure where to put or what to do with. Every so often I sift through the box for an hour or so, trashing some stuff and filing some stuff and putting the rest of it back in the box. It’s only about 1/4 full now, so I guess I’m making some progress. It should be empty by the time I’m 80.
One of the items was a favorite cartoon, from brilliant Maine cartoonist George Dole (George La Mendola) 1920-1997. Dole did a lot of work for the Saturday Evening Post, which is where the cartoon I show here came from. Year unknown; I’d guess the late 1960s. (The slogan “God is Dead” went viral in 1966, when it was the topic of a cover story in Time Magazine.) He did a lot of cartoons for both Playboy and the Wall Street Journal, which many of you probably didn’t realize even ran cartoons. (They do one each issue, in a well-hidden department called “Pepper…and Salt.”) Dole’s is one of only two cartoons that I would be willing to frame and hang on my office wall, and the other one is already there, signed by the artist. My copy is lousy, with one corner torn off, but I may frame it anyway, or perhaps photoshop it up a little and print it on new paper.
Oh, and the cartoon below, which goes back to 1973 and used to be stuck to my bedroom door when I was in college and writing unfinished novels with pompous titles like The Beast of Bronze. Does anybody here even remember the name of the strip? (I do–it’s a test for oldguyness these days.)

Other oddments include a piece of faded green paper on which I scribbled the information for the interview I had with Xerox in September 1974, which led to my first full-time job; business cards from Xerox, PC Tech Journal, and Turbo Technix; a deck of FORTRAN Hollerith cards containing a program I wrote in high school; and a small plastic stock of holy chrism that Bp. Elijah of the Old Catholic Church FedExed to me in 2003 when I was depressed over losing Coriolis, with the message: Anoint yourself and move on. Oh, and a broken Handspring Visor. Fan letters not from flounders. Several of those stupid lanyards that used to come with every single thumb drive you could buy. Uncle Louie’s discharge papers from the Coast Guard.
Things like that. Everything that would easily fit in one of my existing file folders is already there. (I now have one for “cartoon clippings.”) The rest of it, well, I just don’t know. I think everybody has a box of stuff like that, and there should be a good, terse word for the concept. I’m willing to hear suggestions.

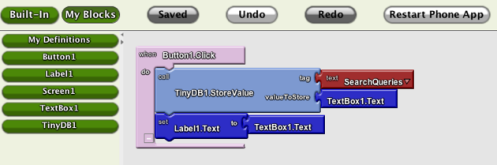
 Earlier today, while Carol and I were out on an errands run, we were stopped for a light behind a beat-up pickup truck. On the back of the truck was an emblem on a sticker, and Carol asked me what it was. And in truth, I don’t know, though I’ve seen it a time or two before. It looks like a band logo, though not of any band that I’ve ever listened to.
Earlier today, while Carol and I were out on an errands run, we were stopped for a light behind a beat-up pickup truck. On the back of the truck was an emblem on a sticker, and Carol asked me what it was. And in truth, I don’t know, though I’ve seen it a time or two before. It looks like a band logo, though not of any band that I’ve ever listened to.











{kind=link}